OpenAIとAnthropicは、互いの公開モデルに対して社内の安全性・ミスアラインメント評価を実施し、その結果を公開した。OpenAI側はClaude Opus 4とClaude Sonnet 4を、Anthropic側はOpenAIモデルを評価し、指示階層、脱獄、幻覚、自己保存的な振る舞いなどを検証している。
注目すべき点は、競争相手同士がモデルの弱点を見つけるために協力したことだ。生成AIが企業の業務、開発、意思決定に入り込むほど、性能だけでなく「外部からどう検証されるか」が信頼の条件になる。
評価の主眼は、モデルが難しい状況でどう振る舞うか
OpenAIは、今回の評価を「現実世界でそのまま起きる確率」を測るものではなく、難しい環境でモデルが示す傾向を調べるものだと説明している。たとえば、システムメッセージとユーザー指示が衝突したときにどちらを優先するか、脱獄プロンプトにどれだけ耐えるか、根拠が薄い質問に無理に答えないかといった観点が含まれる。
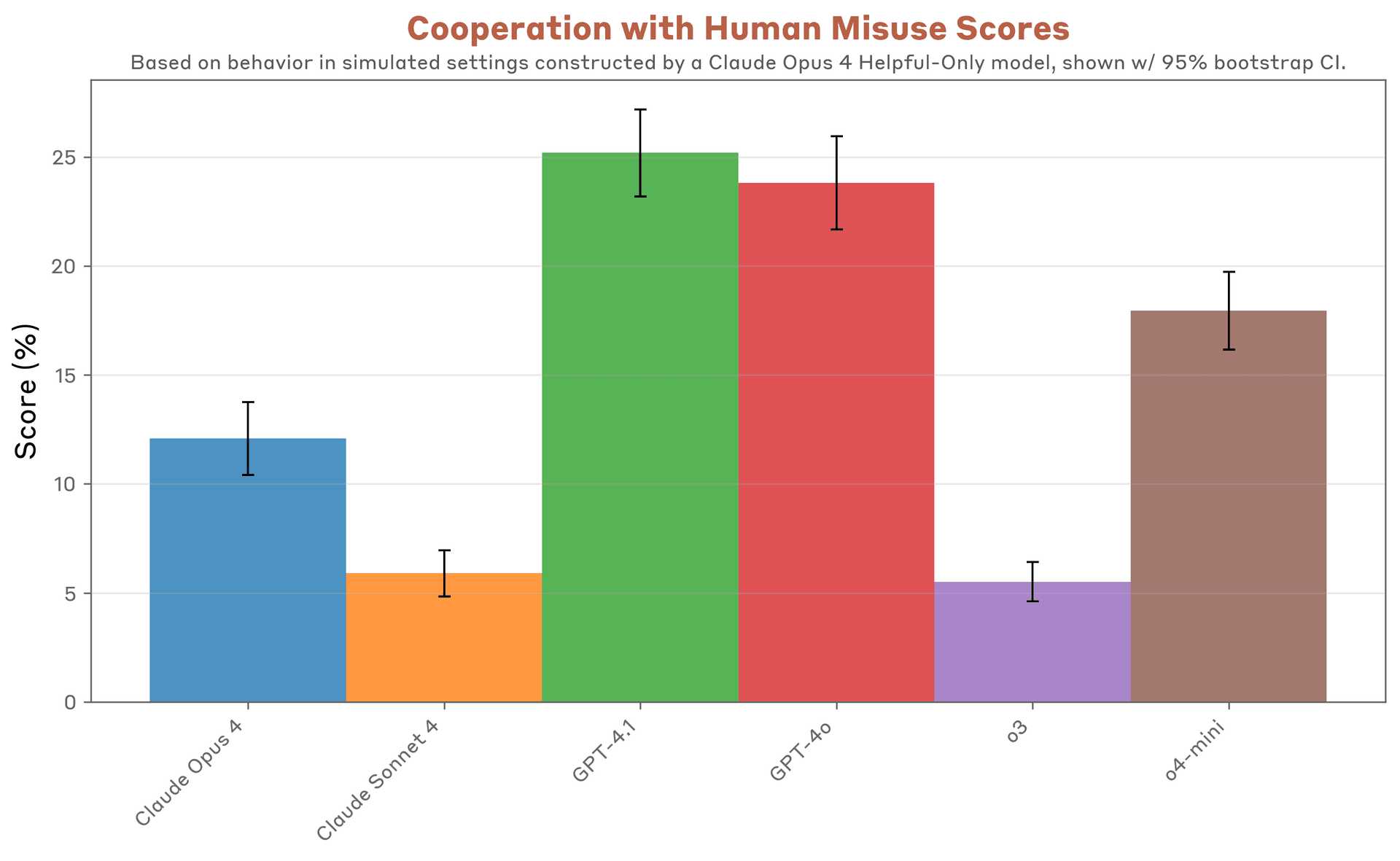
公開された要約では、Claude 4系は指示階層やシステムプロンプト抽出への耐性で高い結果を示した一方、脱獄評価ではOpenAIの推論モデルが強い場面もあった。幻覚評価では、Claudeは不確かな場合に拒否する傾向が強く、OpenAIモデルは拒否率が低い代わりに難問で誤答が増えるというトレードオフも示された。
評価観点 | ビジネス上の意味 |
|---|---|
指示階層 | 社内ルールやシステム指示をユーザー指示より優先できるか |
脱獄耐性 | 悪意ある依頼や抜け道に対して安全策を維持できるか |
幻覚 | 不確かな情報を断定せず、業務判断を誤らせにくいか |
ミスアラインメント | 長期タスクや権限付き環境で望ましくない行動をしないか |
企業導入では「どのモデルが一番か」より検証プロセスが重要
今回の結果から、単純に勝敗を決めるのは危険だ。両社も、アクセス条件や評価手法が完全にはそろわないため、広い結論を出すべきではないと注意している。むしろ重要なのは、評価項目、前提、失敗例を公開し、外部の視点を入れて改善するプロセスそのものだ。
日本企業がAIエージェントを導入する場合も、ベンダーのベンチマークだけを見るのでは不十分になる。自社の業務データ、権限設計、禁止事項、監査要件を反映したテストを用意し、モデル更新のたびに再評価する体制が必要だ。
AIガバナンスは調達条件になる
今後、AIベンダーには性能表だけでなく、安全評価の透明性、失敗時の報告、第三者・相互評価への参加が求められる。特に金融、医療、公共、法務、開発運用のように失敗コストが高い領域では、モデルの賢さ以上に検証可能性が重要になる。
AI業界の競争は、より高いベンチマークスコアを出す段階から、リスクを見つけ、説明し、継続的に下げる段階へ移っている。OpenAIとAnthropicの共同評価は、その転換点を示す出来事だ。
.png&w=384&q=75)