

Microsoftは2026年3月30日、Microsoft 365の新機能「Copilot Cowork」をFrontierプログラムで提供開始した。あわせて、深掘り調査エージェント「Researcher」にマルチモデルAI連携機能「Critique」「Council」を導入し、AIリサーチの精度を大幅に向上させている。
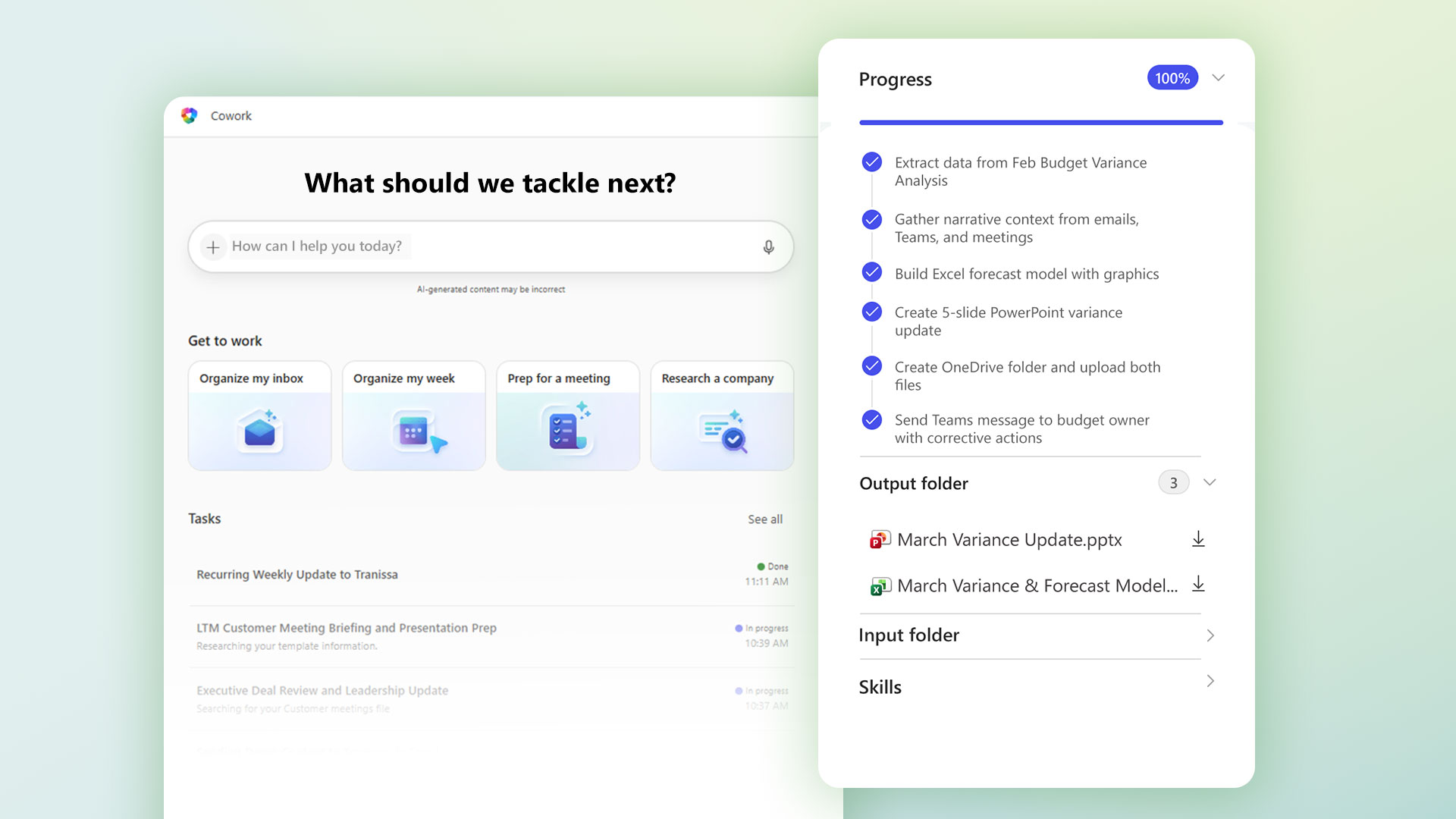
Copilot Cowork:長時間マルチステップ作業を委任
Copilot Coworkは、Anthropicの「Claude Cowork」技術基盤をMicrosoft 365に統合した新機能だ。ユーザーが望む成果を記述すると、Coworkが計画を作成し、ツールやファイルを横断しながら作業を遂行する。カレンダー管理や日次ブリーフィングなどのスキルが組み込まれており、月次予算レビューのような繰り返し作業にも対応する。
「Coworkの新機能は、コンテンツや回答を生成することではなく、ステップをつなぎ、タスクを調整し、日常のワークフロー全体をフォローすることです」── Barton Warner氏(Capital Group SVP of Enterprise Technology)
Critique:GPTが生成、Claudeがレビュー
Researcherの新機能「Critique」は、生成と評価を分離するマルチモデルアーキテクチャを採用。OpenAIのGPTがタスク計画・情報検索・初稿生成を担当し、AnthropicのClaudeがレビュアーとして品質チェックを行う。
Claudeによるレビューは以下の3つの観点で実施される:
- ソース信頼性評価:権威性のある適切なソースの使用を重視
- レポート完全性:リクエストの意図を網羅的に満たしているか評価
- エビデンスグラウンディング:主要な主張が信頼できるソースに正確に紐づいているか検証
業界標準ベンチマーク「DRACO」(Deep Research Accuracy, Completeness, and Objectivity)では、従来のシングルモデル方式と比較して総合スコアが+7.0ポイント向上。Perplexity Deep Research(Claude Opus 4.6モデル)と比較して13.88%の改善を達成した。
評価軸 | 改善幅 |
|---|---|
分析の広さ・深さ | +3.33 |
プレゼンテーション品質 | +3.04 |
事実精度 | +2.58 |
引用品質 | 向上(既存ソースの活用改善) |
Council:複数モデルの並列比較
もう一つの新機能「Council」は、AnthropicとOpenAIのモデルを同時に独立実行し、それぞれのレポートを出力するアプローチだ。専用の判定モデルが両レポートを評価し、見解が一致する部分・分岐する部分・各モデル固有の洞察をまとめて提示する。Critiqueが「2モデル協業で1つの高品質な回答」を目指すのに対し、Councilは「複数視点の比較」による多角的な理解を提供する。
注目ポイント
CritiqueとCouncilは現在Frontierプログラム参加者向けに提供されている。異なるAI企業のモデルを組み合わせるマルチモデル戦略は、単一モデルの限界を超える新たなアプローチとして注目される。ただし、Frontierプログラムへの参加が前提であり、一般提供の時期は未定だ。
.png&w=384&q=75)

